Treinei um modelo que adivinha se uma pessoa ganha mais de 50 mil dólares por ano com quase 88% de acurácia. Poderia parar por aqui, mostrar o número e receber os parabéns. Mas o número não é a parte interessante. A parte interessante é descobrir em que o modelo se apoia pra acertar. E quando eu abri a caixa preta, o que encontrei lá dentro me incomodou um pouco.
Usei o Adult Census Income, um dataset clássico com 48.842 pessoas do censo americano e a tarefa de prever quem ganha acima de 50 mil. É um problema de brinquedo, mas ele expõe um problema bem real: um modelo pode estar certo pelos motivos errados, e a acurácia nunca vai te avisar disso.
Primeiro, a armadilha de sempre
Antes de confiar em qualquer acurácia, eu olho o balanço das classes. Aqui, 76,1% das pessoas ganham até 50 mil e só 23,9% passam disso.
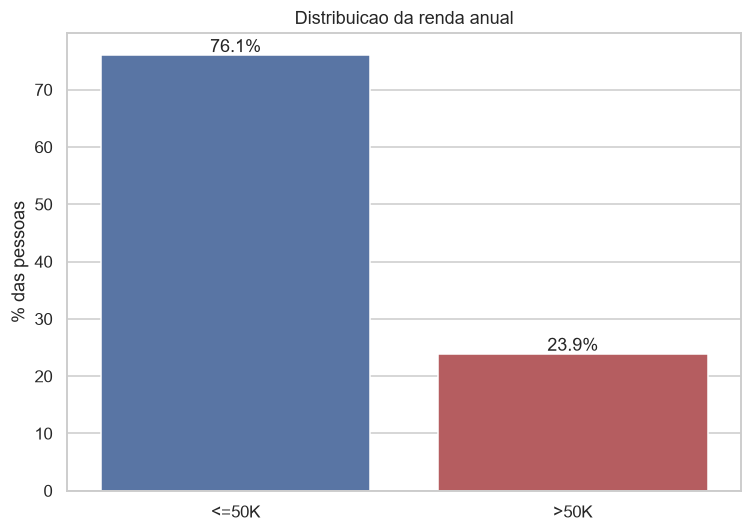
Esse desequilíbrio muda tudo. Um modelo preguiçoso que chuta “ganha pouco” pra todo mundo já acerta 76% das vezes sem aprender nada. Então a régua de verdade não é 0%, é 76%. Eu já tinha escrito sobre essa cilada em quando 82% de acurácia é engano, e ela reaparece aqui pontual como sempre.
Treinei três modelos pra comparar. Os números reais do conjunto de teste:
| Modelo | Acurácia | Precisão | Recall | F1 | AUC |
|---|---|---|---|---|---|
| Chute na maioria | 76,1% | - | - | - | - |
| Regressão Logística | 85,3% | 73,6% | 59,8% | 0,66 | 0,904 |
| Random Forest | 85,7% | 73,6% | 62,8% | 0,68 | 0,906 |
| XGBoost | 87,8% | 79,3% | 66,0% | 0,72 | 0,931 |
O XGBoost ganhou em tudo. Mas repare no recall: 66%. Traduzindo, de cada três pessoas que de fato ganham mais de 50 mil, o modelo deixa uma passar batida como se ganhasse pouco. Foram 794 dessas só no teste. A acurácia de 88% esconde esse buraco embaixo do tapete, porque a classe que ele erra mais é justamente a minoria. De novo: o número bonito mente sobre a coisa que importa.
Agora a pergunta que interessa: por quê?
Acurácia me diz se o modelo acerta. Ela não me diz em cima de quê. Pra isso eu uso SHAP, uma técnica que decompõe cada previsão e mostra quanto cada variável empurrou o resultado pra cima ou pra baixo. É o que transforma um modelo de “caixa preta que funciona” em “decisão que dá pra auditar”.
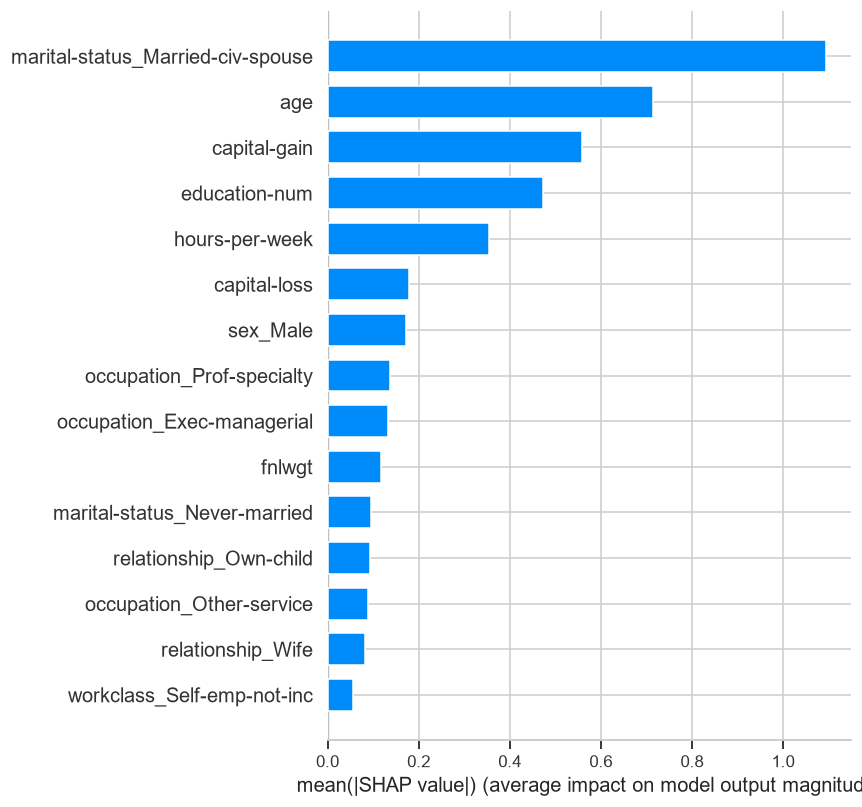
A variável mais influente, disparada, não é educação nem horas trabalhadas. É estado civil, especificamente ser casado. Logo depois vêm idade, ganho de capital e escolaridade. O gráfico de dispersão dá ainda mais textura, mostrando não só o peso de cada variável mas a direção:
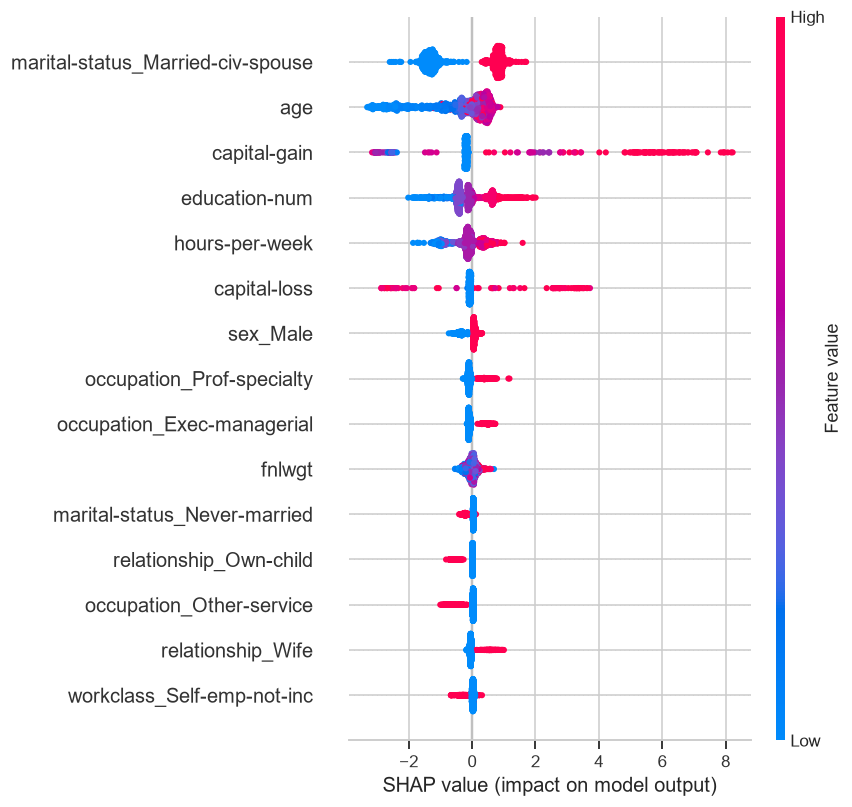
E é aqui que a coisa fica desconfortável.
Três coisas que o SHAP me obrigou a encarar
O modelo acha que casamento prevê dinheiro. Ele não está errado nos dados. Mas casar não faz ninguém ganhar mais. O que acontece é que, no censo americano de 1994, “casado” se correlaciona com homens mais velhos em arranjos familiares tradicionais, que por sua vez ganhavam mais. O modelo capturou um retrato social de uma época e o vestiu de regra de causa e efeito. Se alguém usasse isso pra decidir crédito ou contratação, estaria penalizando solteiros por uma correlação que não tem nada de causal. A acurácia aplaudiria. O SHAP é que levanta a mão.
O modelo aprendeu o gap de gênero. Nos dados, 30,4% dos homens passam dos 50 mil contra apenas 10,9% das mulheres.
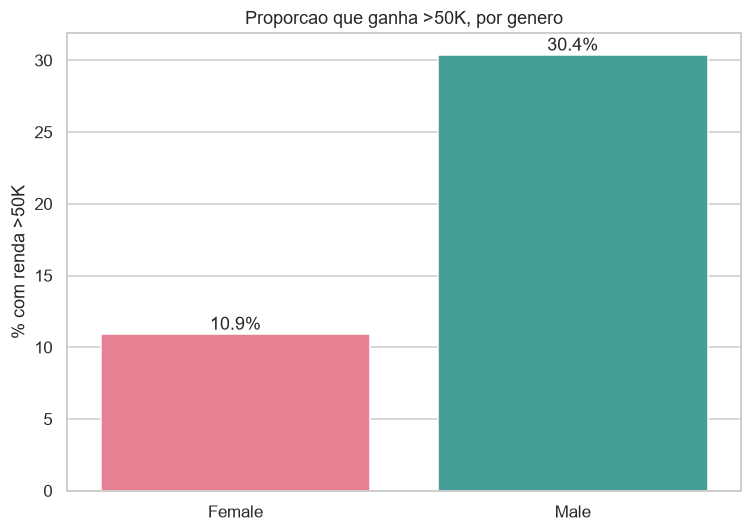
O ser-homem aparece entre as variáveis que o modelo usa pra prever renda alta. Faz todo sentido estatístico e é eticamente um campo minado. Um modelo treinado assim não apenas descreve a desigualdade que existe, ele a perpetua, porque passa a recomendar decisões que assumem essa desigualdade como dado permanente. Sem abrir a caixa preta, ninguém na sala saberia que o gênero estava ali dentro, pesando.
O modelo se agarrou a uma variável que é puro lixo. Entre as dez mais influentes apareceu a fnlwgt, que é um peso amostral do censo, um número administrativo sem nenhuma relação com a vida da pessoa. Não deveria prever nada. O fato de ele ter alguma importância é o modelo encontrando padrão no ruído. É exatamente o tipo de coisa que só se enxerga olhando por dentro, e que numa base maior poderia virar um vazamento silencioso de informação que infla a métrica de validação e quebra na vida real.
O que eu tiro disso
A explicabilidade não é enfeite acadêmico nem caixinha de compliance pra marcar. Ela responde uma pergunta diferente da acurácia, e mais importante quando a decisão toca gente: o modelo está certo pelos motivos certos?
Os três achados acima não aparecem em nenhuma métrica de desempenho. O XGBoost com seus 88% e AUC de 0,93 passaria liso em qualquer apresentação. Foi só ao abrir que ficou claro que ele apoia boa parte do acerto em estado civil, em gênero e até em ruído administrativo. Continua sendo um bom modelo pra prever. Seria um péssimo modelo pra decidir qualquer coisa sobre uma pessoa real.
E essa é a lição que eu levo pra qualquer projeto sério. Otimizar a métrica é a parte fácil, qualquer biblioteca faz. O trabalho de verdade começa quando você pergunta o que o modelo aprendeu pra chegar naquele número, e tem coragem de não gostar da resposta.
Comentários